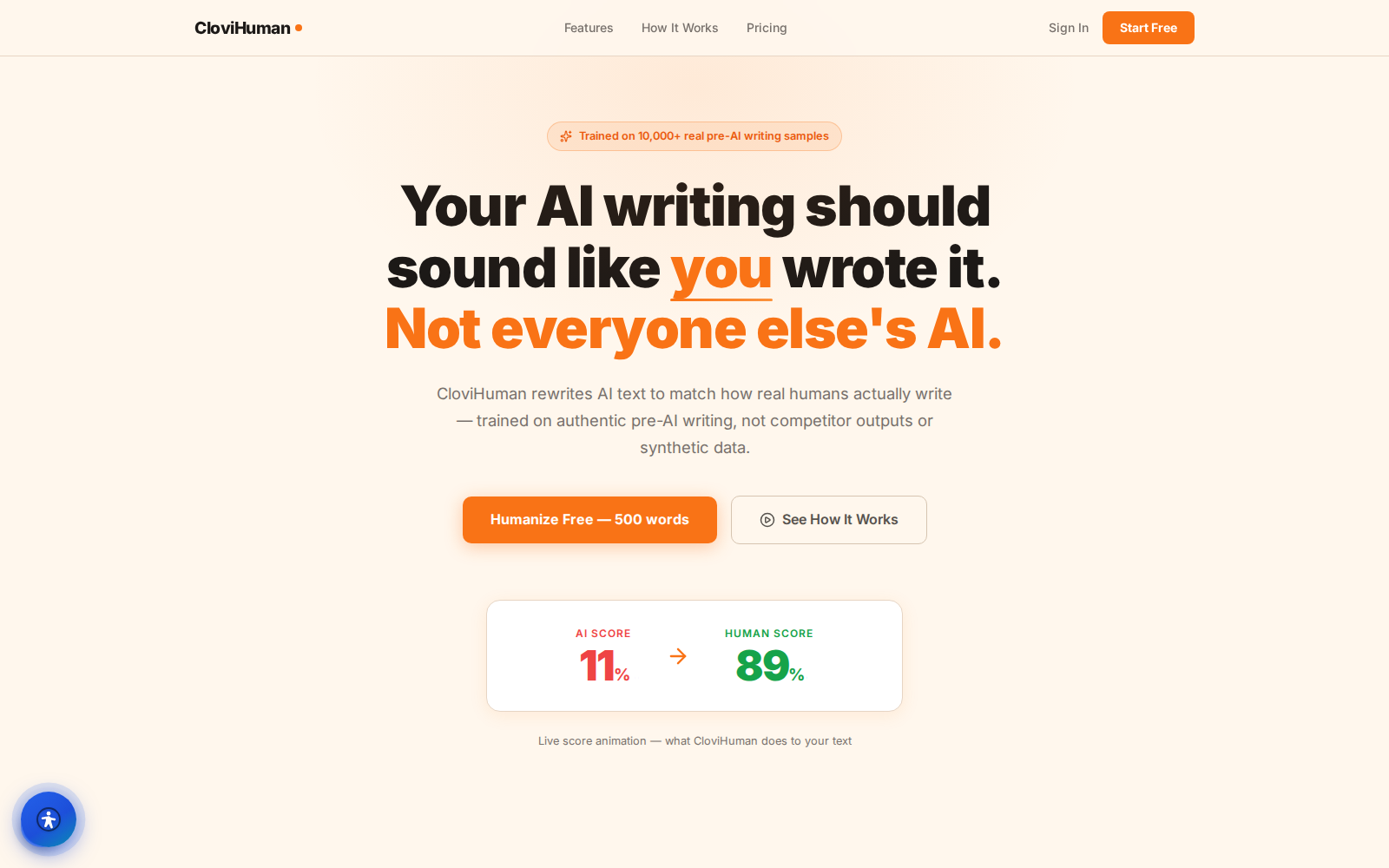
CloviHuman — turn AI drafts into prose that reads like you wrote it
An AI text humanizer that rewrites in real voice profiles and shows two independent detector scores, so polished drafts stay yours.
TL;DR
- Rewrite AI-generated text into natural, on-voice prose using style profiles instead of a single generic mode
- Pick the register: business, academic, casual, memoir, or educator, each backed by a retrieval-tuned style library
- Check the result against two independent detectors, including an open-source modern-LLM ensemble
- Keep a searchable history of every rewrite with a change count and confidence reading
- Lifetime access with monthly-renewing word credits, by CloviTek AI
See what's inside — how it works
At a glance
Best for
- Content agencies refreshing and rewording AI first drafts at volume
- In-house marketing and content teams protecting a consistent brand voice
- ESL and non-native writers smoothing drafts into natural English
Integrations
- REST API for humanize and detect endpoints
- JSON output for content pipelines and automation platforms
- CloviTek AI connected suite (CloviNarrate, CloviDecks)
Alternative to
- AI text humanizer and paraphrasing tools
Overview
AI drafts come out fast — but flat, and predictable. They read the same way every single time, which strips away the voice that makes content feel like a person actually wrote it. That's where CloviHuman comes in. It rewrites that text into whatever register a piece needs — casual, formal, somewhere between — and the result can be checked against independent detectors before it ships. No guessing, no crossing fingers and hoping a draft passes.
CloviHuman is an all-in-one AI text humanizer — the kind of tool that does what it says. Voice-profile rewriting, adjustable rewrite intensity, dual detector scoring, and a saved rewrite history, all in one place.
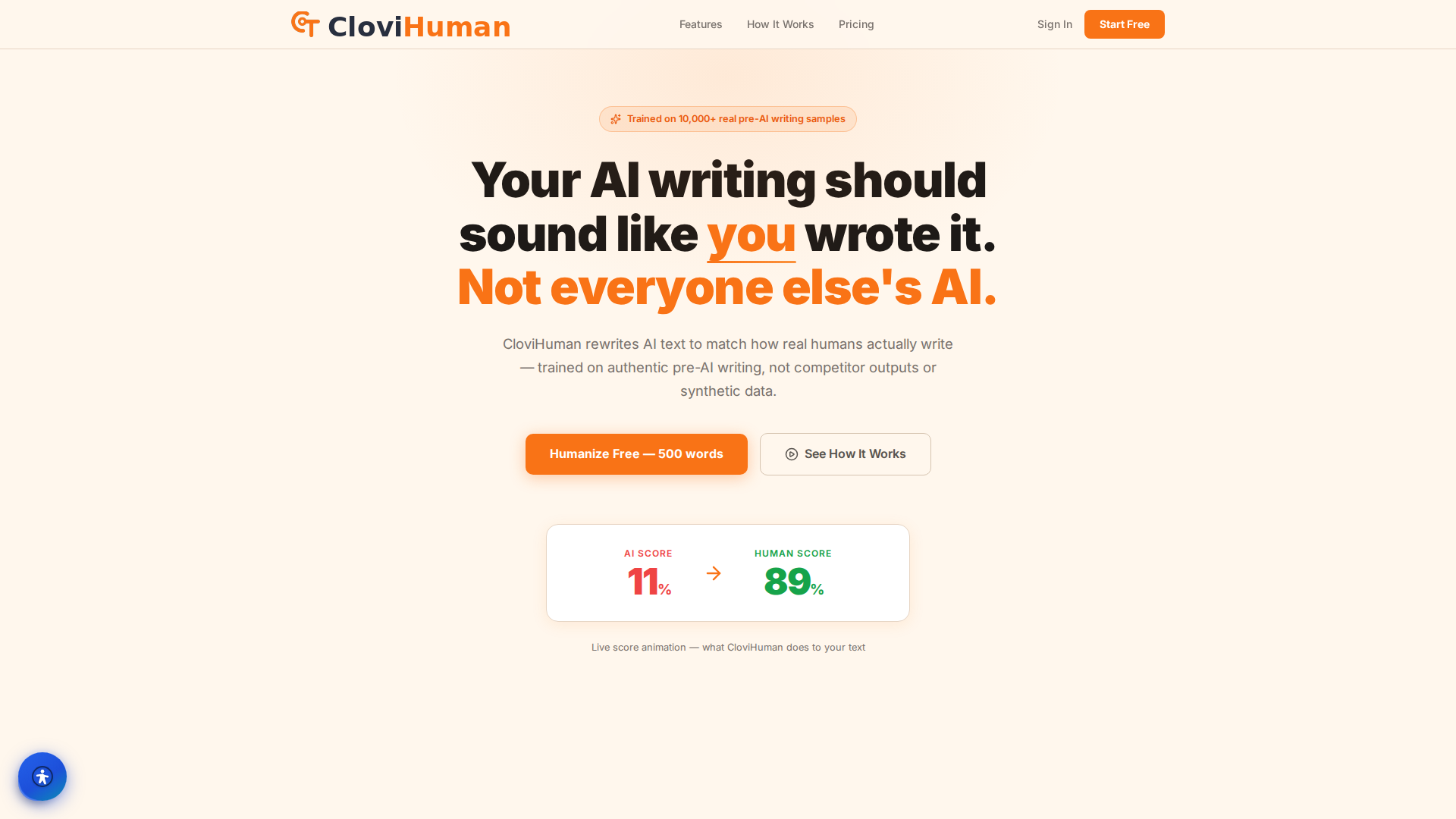
Voice-profile rewriting, not one generic mode
Most rewriters take one pass and flatten everything into the same beige voice. CloviHuman works differently — it rewrites against actual style profiles: Business Professional, Technical Academic, Casual, Storytelling and Memoir, Educator. Each one is grounded in a real library of sample prose, so the output borrows authentic cadence, sentence rhythm, and word choice rather than a vague make-it-sound-human setting. A writer picks the register that fits the piece, and the rewrite leans hard into that target. The result reads like a specific kind of author wrote it — someone with a consistent voice and point of view. Brand and personal voice stay intact across a whole batch of drafts, not just the one piece that got lucky.
Adjustable intensity to balance fidelity and change
A light touch keeps the original meaning nearly word for word, while a heavier pass tears sentences apart and rebuilds them for more natural burstiness. CloviHuman surfaces this as an intensity dial, so the same draft can be nudged gently for a careful edit or reworked harder when the source feels stiff and templated. Calibration runs documented in the project guide tune the prompt toward the patterns real writers actually overuse — things like wide sentence-length variation and punctuation. Every rewrite returns a word-change count, an instant read on how far the text drifted from where it started.
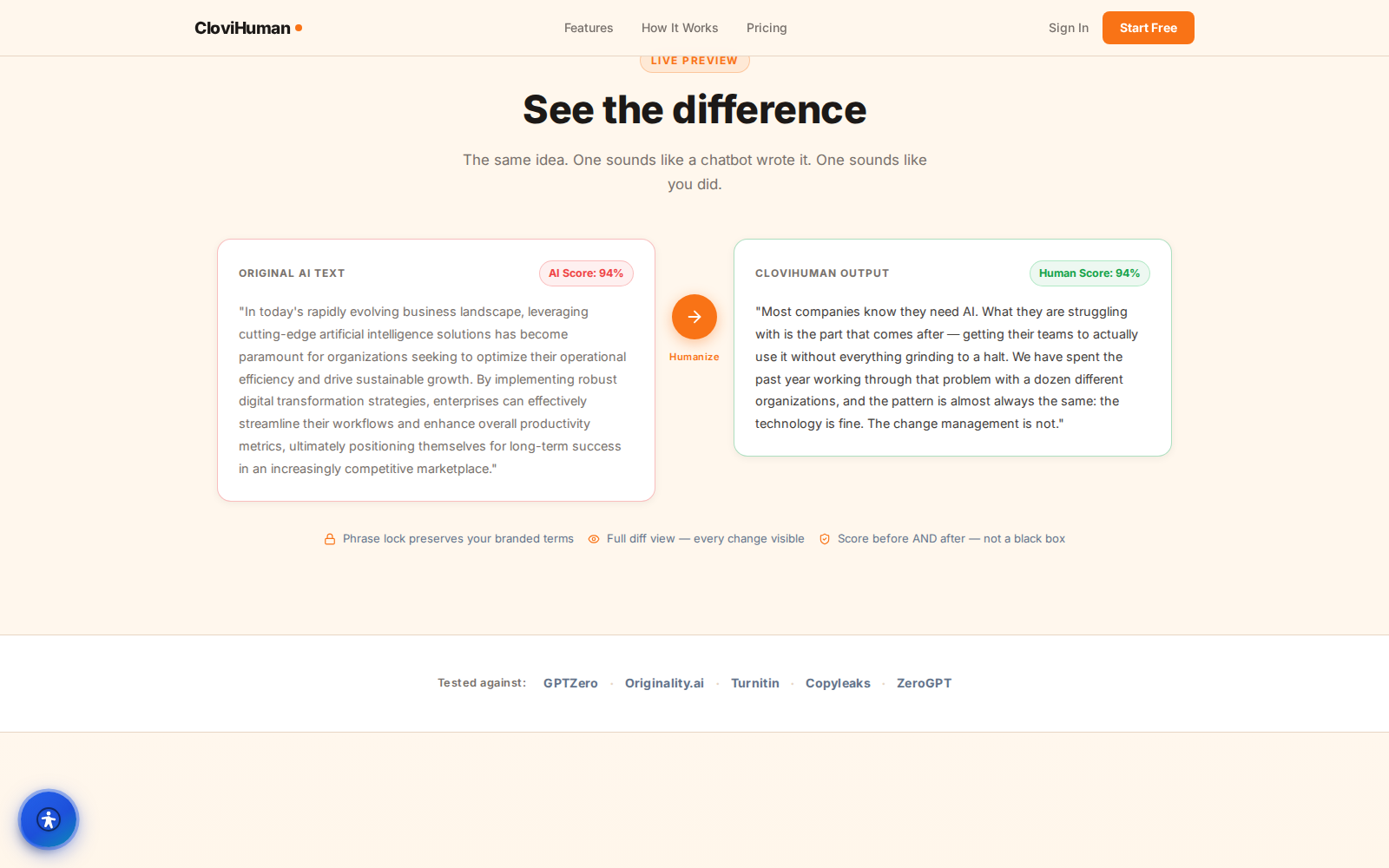
Two independent detector readings
Verification isn't tucked away in a separate tab — it's built right in. CloviHuman ships two detectors working side by side. The in-house one measures how well text matches the target voice. The second is an open-source v2 ensemble that pulls together a modern-LLM-trained DeBERTa model with two other classifiers. The project benchmark shows the v2 ensemble separating machine text from human writing more reliably than the style gauge does, and the documentation doesn't hide the messy truth: scores that land in the middle band are uncertain, not a clear answer either way. Both readings show up together, so a rewrite gets a real sanity-check before it goes live — honest framing kept right up front.
Saved history with change and confidence detail
Every humanize run saves everything — the original snippet, the rewritten output, the chosen style and intensity, how many words changed, even a confidence reading. The whole thing lands in a per-account history instead of vanishing into a throwaway box. That turns CloviHuman into an actual working log: a team can revisit what got rewritten last week, compare approaches across drafts, and keep a paper trail for review. Authentication runs on signed tokens, and each account sees only its own entries. On long projects, that history becomes the thing that makes repeated work easy to track.
REST API and clean JSON for pipelines
Beyond the editor, CloviHuman exposes humanize and detect endpoints that return structured JSON — so the same rewriting and scoring can run inside a content pipeline. A blog workflow, an email sequence, or a batch refresh can call the service directly and read back the humanized text, the change count, and the detector signals. Output is plain data with no watermark slipped into the prose, which keeps it easy to slot into automation platforms and downstream tools. CloviHuman becomes a component in a larger publishing flow rather than only a standalone web app.
CloviHuman is for writers and teams who use AI to move fast but refuse to publish work that sounds like it rolled off an assembly line. It pairs voice-aware rewriting that preserves tone with dual-detector verification and a full history, so the work stays reviewable and on-brand. Pricing is a stacking lifetime deal with monthly-renewing word credits — buy what fits the volume, stack for more — and the connected CloviTek AI studio adds narration and deck tools when a project calls for them. The roadmap ships publicly, roughly once a month, with features voted on by founders actually using the tool. Grab a code, stack to the right tier, and start turning AI drafts into prose that reads like a person wrote it.
Plans & features
Tier 1
$59
Lifetime access for one user. 25,000 humanized words per month (renewing). All five voice profiles, adjustable intensity, in-house detector, full rewrite history. 60-day refund window.
Tier 2
$129
Everything in Tier 1. 75,000 words per month. Open-source v2 detector ensemble unlocked. Priority email support and early access to new style profiles.
Tier 3
$249
Everything in Tier 2. 200,000 words per month. REST API access for humanize and detect endpoints, plus batch JSON output for content pipelines (the high-margin automation feature). Up to 3 seats.
Tier 4
$449
Everything in Tier 3. 500,000 words per month. Up to 8 seats with shared team history and usage dashboard. Higher API rate limits.
Tier 5
$799
Everything in Tier 4. 1,200,000 words per month. Up to 20 seats, top API rate limits, custom voice-profile onboarding, and direct founder support channel.
FAQs
Is CloviHuman a way to cheat AI detectors?
CloviHuman is positioned for legitimate rewriting: refreshing AI drafts, preserving brand voice, and smoothing non-native English. It shows two detector readings so writers can verify output, and the documentation is open that mid-range scores are uncertain rather than a guaranteed pass. No bypass rate or guarantee is claimed.
How are the word credits handled?
Each tier includes a fixed pool of humanized words that renews every month for the life of the deal. Credits are not unlimited, which keeps pricing honest and the service sustainable. Higher tiers raise the monthly pool and add seats and API limits.
What is the difference between the two detectors?
The in-house detector measures how closely text matches a target voice, so it reads as a style-match gauge. The v2 ensemble combines a modern-LLM-trained model with two additional classifiers and separates machine from human passages more reliably in the project benchmark. Both are shown so results can be cross-checked.
Can I use CloviHuman inside my own workflow?
Yes. From Tier 3 up, REST humanize and detect endpoints return structured JSON, so rewriting and scoring can run inside a content pipeline or automation platform. Lower tiers use the web editor with full style profiles and history.
What is the refund policy?
Every tier includes a 60-day refund window and lifetime access to the tier purchased, including the monthly-renewing word credits. Codes can be stacked to move up tiers within the same window.
- Hero: clean screenshot of the editor with an AI draft on the left and the humanized, on-voice output on the right, 1920x1080, no text overlay
- Screenshot: style profile picker showing the five voice profiles with descriptions, 1920x1080
- Screenshot: intensity control plus the change-count and confidence result after a rewrite, 1920x1080
- Screenshot: dual detector panel showing in-house and v2 ensemble scores side by side, 1920x1080
- Screenshot: rewrite history list with original snippet, style, intensity, and changed-word count, 1920x1080
- Screenshot: API request and JSON response for the humanize endpoint in a clean console view, 1920x1080
- ✓ Working humanize endpoint (Claude-backed, RAG style profiles)
- ✓ Adjustable intensity and change-count output
- ✓ In-house detector live (/api/detect)
- ✓ Open-source v2 detector ensemble live (/api/detect/v2)
- ✓ Five voice profiles with retrieval-tuned style library
- ✓ Per-account rewrite history with signed-token auth
- ✓ REST API for humanize and detect endpoints
- ✓ Media: hero + product screenshots prepared (Dashboard, How it works, Output — embedded in gallery above)
- ✓ Public working demo / free trial — clovihuman.com
- ✓ 60-day refund window and lifetime-access terms stated
- ✓ Support SLA: sub-24h responses to reviews and questions
- ✓ Public roadmap — clovihuman.com/roadmap (roadmap page queued)
- ✓ Credit-capped LTD pricing defined across all five tiers (monthly-renewing word credits)
Platform prerequisites (shared, in progress): live billing + Stripe wiring and S3 durable storage are shared infrastructure across CloviTek AI products and are tracked separately. These do not block this listing's page-readiness.
Why CloviTek AI built CloviHuman
I kept running AI drafts for course narration and marketing, and every one landed the same way — competent, sure, but with that flat rhythm that screams "a machine wrote this." Generic humanizers made it worse, swapping one beige voice for another. So I built CloviHuman differently: named style profiles, plus honest dual-detector scoring. A rewrite should sound like a real author, and the verification should never overpromise. It slots into the CloviTek AI productivity suite next to the narration and deck tools, sharing the same plain-data API. Here's the honest part — a detector gives a signal, never a final verdict. A mid-range score means uncertain, and that candor is the whole point. The goal is prose that reads like a person, with nothing hidden about how it got there.
by CloviTek AI · Vitaly Kirkpatrick